Towards Model-free Stellar Chemical Abundances. Potential Applications In The Search For Chemically Peculiar Stars In Large Spectroscopic Surveys
Chemical abundance determinations from stellar spectra are challenged by observational noise, limitations in stellar models, and departures from simplifying assumptions.
While traditional and supervised machine learning methods have made remarkable progress in estimating atmospheric parameters and chemical compositions within existing physical models, these factors still constrain our ability to fully exploit the vast data sets provided by modern spectroscopic surveys.
We aim to develop a self-supervised, disentangled representation learning framework that extracts chemically meaningful features directly from spectra, without relying on externally imposed label catalogs.
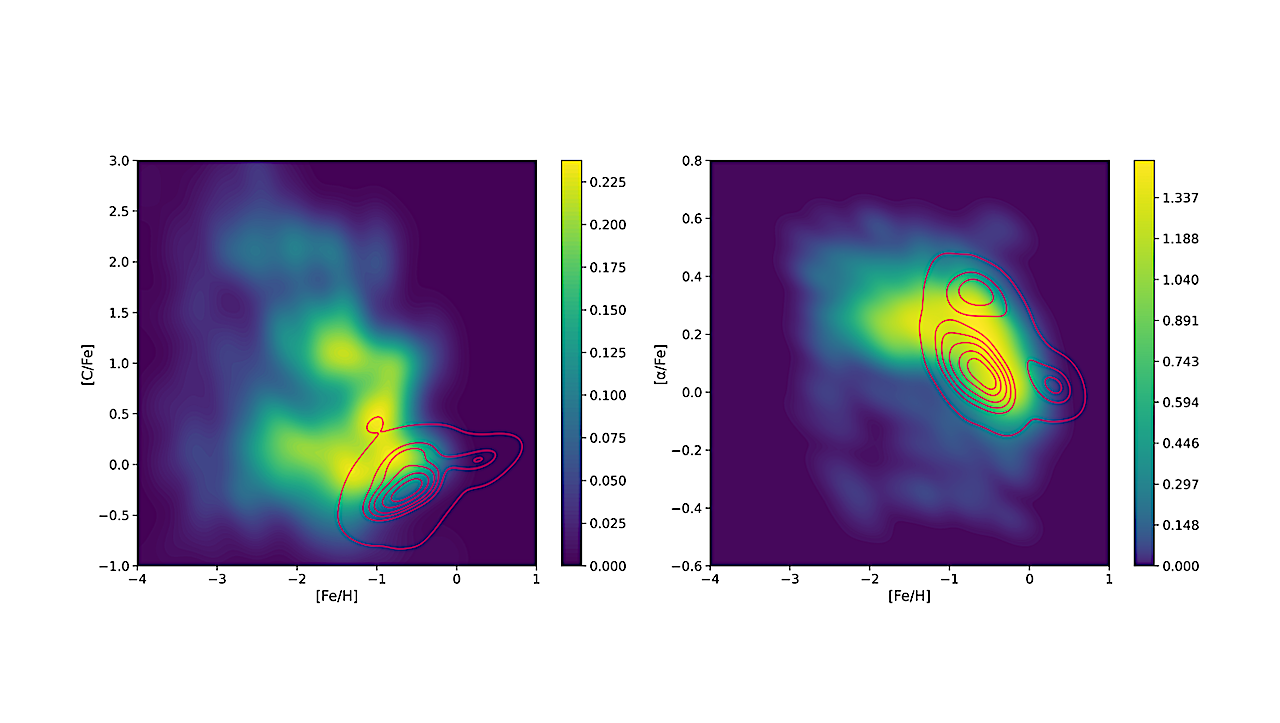
We build a variational autoencoder-based representation learning model with physics-inspired structure: multiple decoders each focus on spectral regions dominated by a particular element, enforcing that each latent dimension maps to a single abundance. To evaluate the potential application of our framework, we trained and validated the model on low-resolution, low signal-to-noise synthetic spectra focusing on [Fe/H], [C/Fe], and [α/Fe].
We then demonstrate how the trained model can be used to flag stars as chemically enhanced or depleted in these abundances based on their position within the latent distribution. Our model successfully learns a representation of spectra whose axes correlate tightly with the target abundances (r=0.92±0.01 for [Fe/H], r=0.92±0.01 for [C/Fe], r=0.82±0.02 for [α/Fe]).
The disentangled representations provide a robust means to distinguish stars based on their chemical properties, offering an efficient and scalable solution for large spectroscopic surveys.
Theosamuele Signor, Paula Jofré, Hernan Lira, Sara Vitali, Luis Martí, Nayat Sánchez-Pi
Comments: 16 pages, 11 figures, accepted on A&A
Subjects: Solar and Stellar Astrophysics (astro-ph.SR); Astrophysics of Galaxies (astro-ph.GA); Instrumentation and Methods for Astrophysics (astro-ph.IM)
Cite as: arXiv:2511.09733 [astro-ph.SR](or arXiv:2511.09733v1 [astro-ph.SR] for this version)
https://doi.org/10.48550/arXiv.2511.09733
Focus to learn more
Related DOI:
https://doi.org/10.1051/0004-6361/202555376
Focus to learn more
Submission history
From: Theosamuele Signor
[v1] Wed, 12 Nov 2025 20:44:49 UTC (10,359 KB)
https://arxiv.org/abs/2511.09733
Astrobiology, Astrochemistry,