Early Selection Of The Amino Acid Alphabet Was Adaptively Shaped By Biophysical Constraints Of Foldability
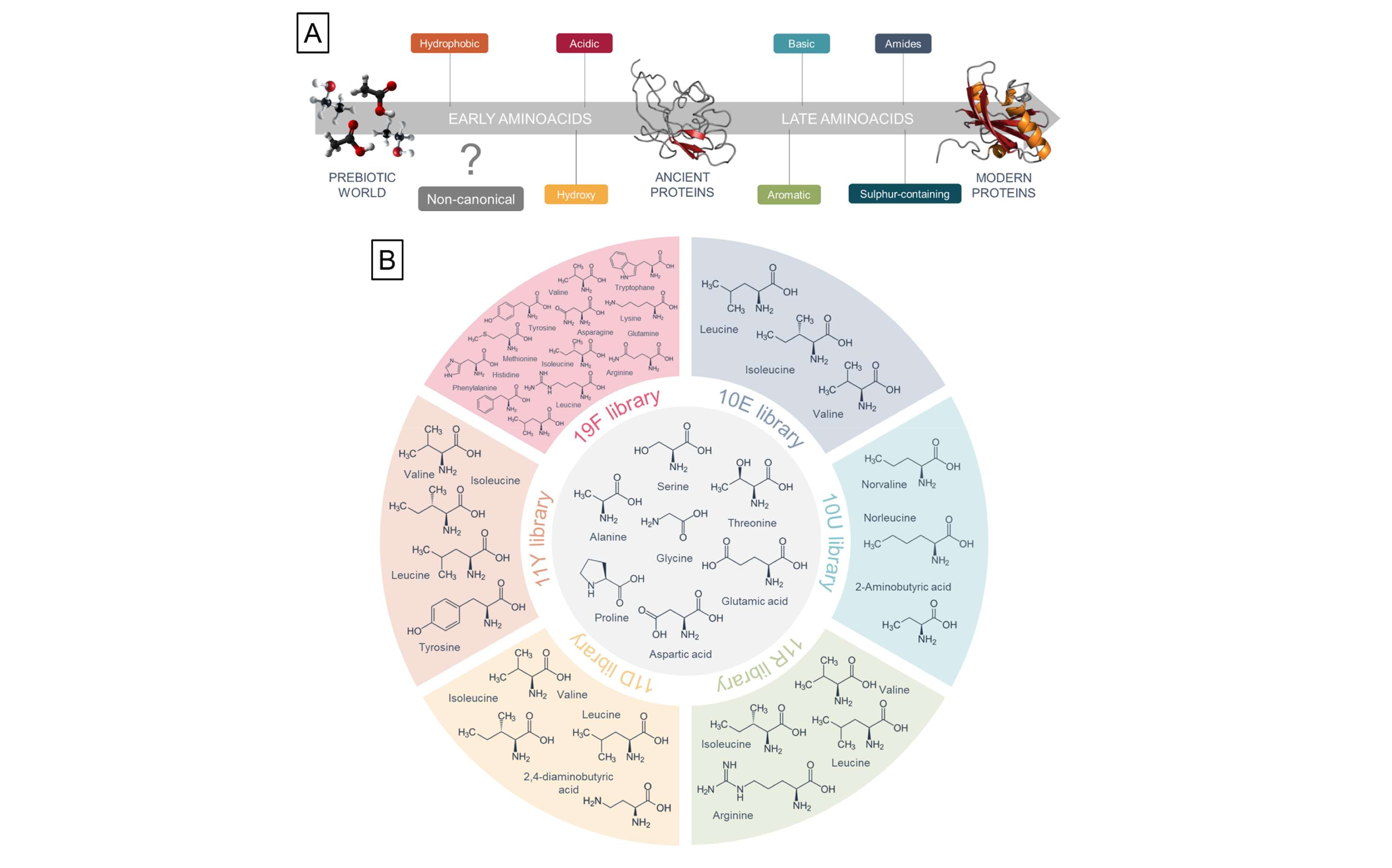
Whereas modern proteins rely on a quasi-universal repertoire of 20 canonical amino acids (AAs), numerous lines of evidence suggest that ancient proteins relied on a limited alphabet of 10 ‘early’ AAs, and that the 10 ‘late’ AAs were products of biosynthetic pathways.
However, many non-proteinogenic AAs were also prebiotically available, which begs two fundamental questions: Why do we have the current modern amino acid alphabet, and Would proteins be able to fold into globular structures as well if different amino acids comprised the genetic code? Here, we experimentally evaluated the solubility and secondary structure propensities of several prebiotically relevant amino acids in the context of synthetic combinatorial 25-mer peptide libraries. The most prebiotically abundant linear aliphatic and basic residues were incorporated along with or in place of other early amino acids to explore these alternative sequence spaces.
We show that foldability was a critical factor in the selection of the canonical alphabet. Unbranched aliphatic and short-chain basic amino acids were purged from the proteinogenic alphabet despite their high prebiotic abundance because they generate polypeptides that are over-solubilized and have low packing efficiency. Surprisingly, we find that the inclusion of a short-chain basic amino acid also decreases polypeptides’ secondary structure potential.
Our results support the view that despite lacking basic residues, the early canonical alphabet was remarkably adaptive at supporting protein folding and explain why basic residues were only incorporated at a later stage of the alphabet evolution.
Mikhail Makarov, Alma C. Sanchez Rocha, Robin Krystufek, Ivan Cherepashuk, Volha Dzmitruk, Tatsiana Charnavets, Anneliese M. Faustino, Michal Lebl, Kosuke Fujishima, View ORCID ProfileStephen D. Fried, ProfileKlara Hlouchova
https://www.biorxiv.org/content/10.1101/2022.06.14.495995v2
doi: https://doi.org/10.1101/2022.06.14.495995
Astrobiology,