Modeling a Near-optimal Genetic Code

Researchers have created a model that may explain the complexities of the origins of life. Their work, which appears in the Journal of the Royal Society Interface, offers new insights into how RNA signaling likely developed into the modern “genetic code.”
“Our model shows that today’s genetic code probably resulted from a combination of selective forces and random chance,” explained Justin Jee, a doctoral student at NYU School of Medicine and the paper’s lead author.
The study’s other co-authors included: Bud Mishra, who has appointments at NYU’s Courant Institute of Mathematical Sciences and the Sackler Institute of Graduate Biomedical Sciences at NYU School of Medicine; Andrew Sundstrom of the Courant Institute; and Steven Massey, an assistant professor in the University of Puerto Rico’s Department of Biology.
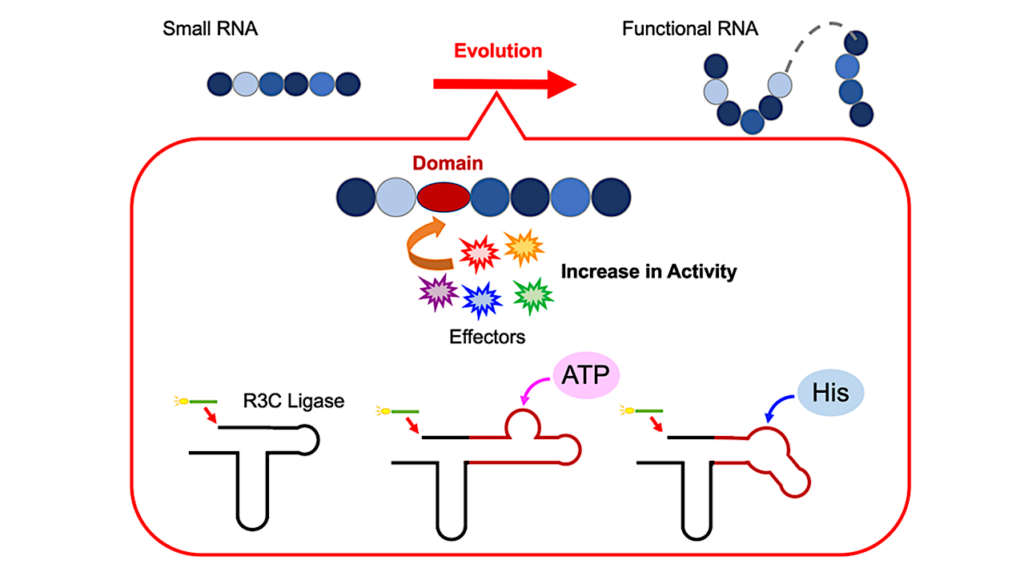
The researchers sought to account for the composition of the genetic code, which allows proteins to be built from amino acids with high specificity based on information stored in a RNA or DNA genome. This translation process between the nucleic acids and amino acids is remarkably and mysteriously universal; the same code is shared in all organisms from bacteria to human beings. At the same time, the genetic code is nearly, but not completely, optimal in terms of how “good” it is at specifying particular amino acids for particular nucleic acid sequences.
Since the code’s discovery in the 1960’s, researchers have wondered: how is it that a near-optimal code became so universal?
To address this question, the researchers created a model of genetic code evolution in which multiple “translating” RNAs and “genomic” RNAs competed for survival. Specifically, the translating RNAs were able to link amino acids together based on information stored in genomic RNA, but with varying levels of specificity.
In running computer simulations of RNA interactions, they could see two phenomena. First, it was necessary for the translating and genomic RNAs to organize into cells, which aided the coordination of a code between the translating and genomic RNAs. Second, selective forces led a single set of translating RNAs to dominate the population. In other words, the emergence of a single, universal, near-optimal code was a natural outcome of the model. Even more remarkably, the results occurred under realistic conditions–specifically, they held under parameters such as protein lengths and rates of mutation that likely existed in a natural RNA world.
“The most elegant ideas in this paper are rather obvious consequences of a well-studied model based on sender-receiver games,” noted Mishra, the paper’s senior author. “Yet the results are still very surprising because they suggest, for example, that proteins, the most prized molecules of biology, might have had their origin as undesirable toxic trash. Other studies based on phylogenomic analysis seem to be coming to similar conclusions independently.”
###
This research was funded by National Science Foundation grants CCF-0836649 and CCF-0926166 as well as by a National Defense Science and Engineering Graduate Fellowship from the U.S. Department of Defense.